Anki, sentence translation excercises
Summary
I have managed to grab Questions and Answers from scanned PDF version of real grammar book and create an Anki deck from it. Although OCR was not perfect at all I was able to restore 50% of all exercises using some smart reg ex replacements in vim editor. Publishing final deck is not possible because of legal issues but I have decided to publish this how-to.
Update: I have decided to provide copy of the deck to anybody who will prove that is owner of the book. Actually I don't know any other way how you can prove that knowing you personally or sending me a digitally signed document where you declare it and will allow me to publish it. Suggestions welcome.
- Quick howto:
- get pdf version of book: http://www.pdfqueen.com/cvicebnice-anglicke-gramatiky or do your own
- save book as text into file
- do some replacements for wrong OCR in any text editor
- run provided python script to create anki import csv file
- create,download deck and templates, import sentences into anki
Longer version
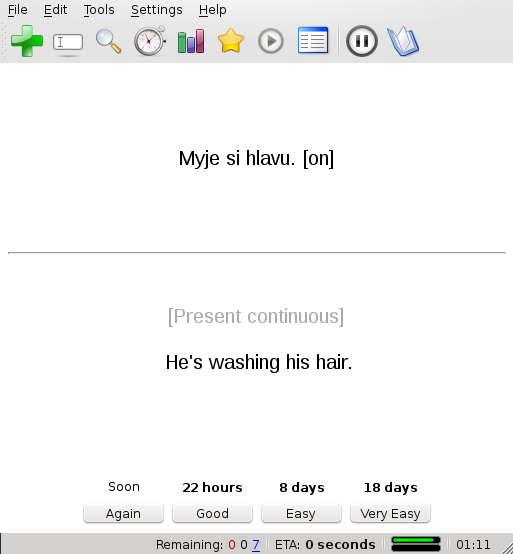
I wrote this script to build Anki deck from PDF version of real Czech/English excercise book where on left page were questions in Czech language and on right page answers in English.
I suppose this two page style to be the best approach to learn foreign language.
Note: I own a printed book but for this purpose I have used PDF version which I have downloaded from internet.
- Search your books PDFs on:
Source PDF is scanned hardcopy of a book where text in PDF is possible to select - means in some extent was text processed by OCR durring scanning.
I opened PDF by Acroread (Adobe PDF reader) and saved as TXT. Click on "File/Save as text ..."
Saved text contained many OCR reading errors which was actually possible to correct. I have used Vim editor with Czech,English spellchecker and number of regular expression patterns to find and correct OCR mistakes.
Final text after an hour in vim editor looked like:
- Trick used:
- chars/strings replacement - correct as much as possible
- delete all rows that were wrong on OCR and nod fixed in previous step
- delete all Czech CHAPTER and LEVEL rows
- save book per chapters into files..
- sorting lines (according ID numbers)
- spell checking and other corrections
For easier processing I spitted file into more files per chapter. One file has looked like:
[XCHAPTER]1. Chapter name <- eng version of chapter [XLEVEL]LEVEL A (AAA-BBB): <- AAA/BBB is start/end numbering of level [XLEVEL]LEVEL B (BBB-CCC): [XLEVEL]LEVEL C (CCC-DDD): 1) Question <- in chzech 1) Answere <- in english 2) Question 2,)Answere <- FAILED TO FIX 3) Question <- ODD 4) Question <- in english (sucession of QA pair changed) 4) Answere <- in chzech 9) Question Excercise2 description. 10) Question 39) Question Excercise3 description. 40) Question .. 351) Question
Actually acroread export to text was a big mess. It took me a few hours to fix it. Chapters and Levels in hardcopy book goes over pages so the same is in PDF. Chapters/Excercises are splited per printed page. The most important was consistency and frequency of Czech questions followed of the same ammount of english answers and fact that Q and A are numbered.
Since sucession of pairs was not stable in the source it was necessary to create some logic which will find out what is Q and what is A in the pair. That is done through external ispell check and then for some chapters where Q is in English on other rules like length of answer etc. Script create Dictionary/Class that holds valid (pair is found and filled) Chapters.Levels.Excercises.Q+A. This class is exported into CSV file that with QA pairs, tags, priorites etc.
Screenshots
Downloads
- My quick and dirty parse script.
- Empty Anki deck. (examples, templates and modified learning options)
APe